Last week, IBM published an article I wrote on using JRuby on Rails with Apache Derby. It concentrates on rapid prototyping/development. I didn't get too heavily into the IDE side of things, but when you add RadRails into the equation it really is nirvana-ish development. Very fun.
I've also been writing a lot on InformIT about Java Concurrency in Practice. I did some fun stuff over there too, like try to turn some Project Euler code into parallel code. I guess technically that succeeded just fine, but is a good example of when parallel code is not any faster. In this case, the algorithm was CPU bound anyways. Even having two cores didn't really help much. Oh well. I treated it like a strength exercise back when I took piano lessons.
Sunday, August 31, 2008
Thursday, August 28, 2008
Search Twitter from Flash
I have updated the Twitter ActionScript API. I added support for search. You are probably aware that search is provided by Summize, who was acquired by Twitter. It is pretty obvious that the APIs have not yet been merged!
Twitter's API is all based on Rails ActiveResource ... which is awesome. It turns any resource (often a database table) into a RESTful service. REST is often associated with XML, but Rails (and thus Twitter) supports it as JSON (Twitter supports ATOM and RSS as well) too. For ActionScript, XML is great. Or I should say POX is great and that is what Rails serves up.
The Twitter Search API is different. It supports two formats: ATOM and JSON. No POX. I went with the ATOM format. For JSON, I would have used Adobe's corelib. It works well, but I didn't want to add the weight. Plus, JSON tends to parse much slower in AS3 than XML. That is because AS3 implements E4X. To get E4X to work with ATOM, you have to be mindful of namespaces. For example, here is the code I used to interate over the entries: for each (entryXml in xml.atom::entry). Here the xml variable is the parsed result from search.twitter.com and atom is a Namespace object. Not as pretty as just xml.entry, but oh well.
Twitter's API is all based on Rails ActiveResource ... which is awesome. It turns any resource (often a database table) into a RESTful service. REST is often associated with XML, but Rails (and thus Twitter) supports it as JSON (Twitter supports ATOM and RSS as well) too. For ActionScript, XML is great. Or I should say POX is great and that is what Rails serves up.
The Twitter Search API is different. It supports two formats: ATOM and JSON. No POX. I went with the ATOM format. For JSON, I would have used Adobe's corelib. It works well, but I didn't want to add the weight. Plus, JSON tends to parse much slower in AS3 than XML. That is because AS3 implements E4X. To get E4X to work with ATOM, you have to be mindful of namespaces. For example, here is the code I used to interate over the entries: for each (entryXml in xml.atom::entry). Here the xml variable is the parsed result from search.twitter.com and atom is a Namespace object. Not as pretty as just xml.entry, but oh well.
Sunday, August 24, 2008
Parsing XML on the Client: JavaScrpt vs. ActionScript
Developer: Wow the JavaScript interpreter on Firefox 3 is awesome, but the one on the new Safari is even better. It is a great time to be a JavaScript developer!
Me: It is still a lot slower than ActionScript.
Developer: Oh don't quote me old numbers, the new browsers are so much faster.
Me: Still slower than ActionScript.
Developer: Maybe slower at doing useless things like calculating prime numbers. Who would do that in a browser anyways? The new browsers are fast at doing realistic things.
Me: But still slower than ActionScript.
Developer: Show me some proof on something realistic, like parsing XML coming back from an Ajax call.
Me: [Whips together a servlet for producing huge chunks of XML and some JS and a SWF for calling it and doing a DOM parse.] Alright let's see the results of these tests...
Everything is O(N), as you would expect, and can verify by doing a linear regression of XML document size vs. parse time. Safari 4 is much faster than Firefox 3, the ratio of their slopes (FF3/S4) = 2.95. But they both lose badly to ActionScript 3 (running Flash Player 10, RC2), (FF3/AS3) = 6.36 and (S4/AS3) = 2.16. Maybe IE can do better, should we give it a try?
Developer: Now you are being a jerk.
Me: It is still a lot slower than ActionScript.
Developer: Oh don't quote me old numbers, the new browsers are so much faster.
Me: Still slower than ActionScript.
Developer: Maybe slower at doing useless things like calculating prime numbers. Who would do that in a browser anyways? The new browsers are fast at doing realistic things.
Me: But still slower than ActionScript.
Developer: Show me some proof on something realistic, like parsing XML coming back from an Ajax call.
Me: [Whips together a servlet for producing huge chunks of XML and some JS and a SWF for calling it and doing a DOM parse.] Alright let's see the results of these tests...
Everything is O(N), as you would expect, and can verify by doing a linear regression of XML document size vs. parse time. Safari 4 is much faster than Firefox 3, the ratio of their slopes (FF3/S4) = 2.95. But they both lose badly to ActionScript 3 (running Flash Player 10, RC2), (FF3/AS3) = 6.36 and (S4/AS3) = 2.16. Maybe IE can do better, should we give it a try?
Developer: Now you are being a jerk.
Thursday, August 21, 2008
Automounting a Drive in OSX
One of my colleagues had an interesting question for me. We needed to auto-mount a Windows drive from a Mac. The Mac was being used to automatically create screenshots of web pages on various Mac browsers. It needed to then upload the screenshots to a shared drive. Thus mounting the drive and just doing a copy seemed like the easiest way to go.
Mounting a Windows drive is very easy with a Mac. Just go to Finder -> Go -> Connect to Server -> and then enter smb://some-windows-machine. Automator seemed like the way to go here. I had actually never used it, but it proved quite easy. Here is what it looked like for me:
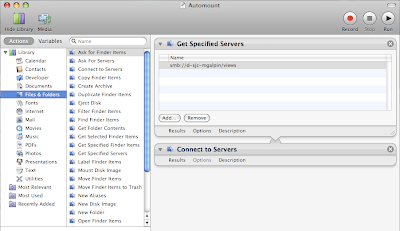 As you can see from the screenshot, I used the Actions -> Files & Folders. I first selected the Get Specified Servers action and added the same URL that I normally used to manually mount the drive. I then added a Connect to Servers action. You will want to test it once, so that you can submit your credentials while making sure to add the credentials to your Keychain. Next, you'll want to do Saves As and change the format to Application. Now to get to execute the Application automatically at startup, go to System Preferences -> Accounts -> Login Items and then browse to wherever you saved the application. Re-boot and that's it!
As you can see from the screenshot, I used the Actions -> Files & Folders. I first selected the Get Specified Servers action and added the same URL that I normally used to manually mount the drive. I then added a Connect to Servers action. You will want to test it once, so that you can submit your credentials while making sure to add the credentials to your Keychain. Next, you'll want to do Saves As and change the format to Application. Now to get to execute the Application automatically at startup, go to System Preferences -> Accounts -> Login Items and then browse to wherever you saved the application. Re-boot and that's it!
Mounting a Windows drive is very easy with a Mac. Just go to Finder -> Go -> Connect to Server -> and then enter smb://some-windows-machine. Automator seemed like the way to go here. I had actually never used it, but it proved quite easy. Here is what it looked like for me:
 As you can see from the screenshot, I used the Actions -> Files & Folders. I first selected the Get Specified Servers action and added the same URL that I normally used to manually mount the drive. I then added a Connect to Servers action. You will want to test it once, so that you can submit your credentials while making sure to add the credentials to your Keychain. Next, you'll want to do Saves As and change the format to Application. Now to get to execute the Application automatically at startup, go to System Preferences -> Accounts -> Login Items and then browse to wherever you saved the application. Re-boot and that's it!
As you can see from the screenshot, I used the Actions -> Files & Folders. I first selected the Get Specified Servers action and added the same URL that I normally used to manually mount the drive. I then added a Connect to Servers action. You will want to test it once, so that you can submit your credentials while making sure to add the credentials to your Keychain. Next, you'll want to do Saves As and change the format to Application. Now to get to execute the Application automatically at startup, go to System Preferences -> Accounts -> Login Items and then browse to wherever you saved the application. Re-boot and that's it!
Tuesday, August 19, 2008
Cache Discussions
My post about using MySQL for caching got picked up by reddit and viewed a few thousand times. It sparked some discussion, but unfortunately it has been spread out on a few different sites. So I decided to aggregate them here.
"Here's a big reason to use MemCached: expiry!
Let's say you only want to do a complicated query once every fifteen minutes. Do it once, put it in a cache by key with an expiry of 15 minutes. Let memcached worry about when to take it out for you."
Yes, this is a good reason to use memcached. I used this pattern for the aggroGator, with Google's version of memcached. Which reminds me that Part 3 of the series I wrote on GAE is out... Anyways, in that app, RSS feed results are cached in memcached with a five minute poll (initiated client-side, so only polling for logged in users.)
Expiry is the cache eviction policy for memcached, where as any database cache is going to be more of an LRU policy. There will be cases where expiry is more useful, but I would actually guess that LRU is appropriate for the majority of use cases...
"MySQL memory table is not as fast as memcached. Depending on your data, memcached is 3X times or more as fast for get/set (select/insert)."
Really? I would love to see some objective results for this. Of course it would have to be an apples-to-apples comparison. The data would need to be retrieved from a cache node on separate physical machine and for the MySQL cache, it would need to be a select by primary key. Now I wouldn't be terribly surprised if memcached was slightly faster, but 3X? I would be even more surprised if a put/insert was faster at all.
"This has been said many times. MySQL and memcached serve different purposes. Memcached is used to store processed data, while MySQL generally contains raw, normailized data, which needs lots of complex queries and other processing."
I actually mentioned this at the end of my post... So obviously I agree. But I have a feeling that people use memcached to cache a lot of data that is not very processed at all. Also, the last line is very misleading. You do not need to do much normalizing of your data. I can tell you that anybody doing federated database systems have to do a lot of de-normalizing of their data. And complex queries and other processing? That is just silly.
"Facebook needs memcache for the obvious reason that it's pages are highly complex and include many pictures."
Eh? Don't see how pictures would matter... But if Facebook is using memcache for HTML fragments, then I would agree that this is the right kind of cache. I don't know if this is the case or not. Other things like my list of friends or my contact info would be a poor choice for memached. Something like the Facebook feed... That is a lot tougher. There are limits to what you can cache, since the feed changes a lot and you might have a low tolerance for stale data. You might be able to create HTML fragments for the stories and cache those?
" Also, fewer of Facebooks pages are time-critical when compared to eBay. On eBay you basically can't cache a page rendering (memcache) if it has less than a minute
of auction time left"
Item listings are certainly time-critical, i.e you expect the price to be accurate when you are looking at a listing and considering bidding on it. This is true regardless of the time remaining, being less than a minute doesn't matter too much. However, that is just one page, many other pages are not so sensitive, but they are very dynamic.
When it comes to picking between MySQL and memcached, I would first say: are you using an ORM but need caching? If the data is being accessed through ORM, then your cache layer should be a database, not memcached. Again the only exception I could see to this would be a graph, i.e. data that is hard to describe relationally (requires self referential foreign keys, etc.)
"Here's a big reason to use MemCached: expiry!
Let's say you only want to do a complicated query once every fifteen minutes. Do it once, put it in a cache by key with an expiry of 15 minutes. Let memcached worry about when to take it out for you."
Yes, this is a good reason to use memcached. I used this pattern for the aggroGator, with Google's version of memcached. Which reminds me that Part 3 of the series I wrote on GAE is out... Anyways, in that app, RSS feed results are cached in memcached with a five minute poll (initiated client-side, so only polling for logged in users.)
Expiry is the cache eviction policy for memcached, where as any database cache is going to be more of an LRU policy. There will be cases where expiry is more useful, but I would actually guess that LRU is appropriate for the majority of use cases...
"MySQL memory table is not as fast as memcached. Depending on your data, memcached is 3X times or more as fast for get/set (select/insert)."
Really? I would love to see some objective results for this. Of course it would have to be an apples-to-apples comparison. The data would need to be retrieved from a cache node on separate physical machine and for the MySQL cache, it would need to be a select by primary key. Now I wouldn't be terribly surprised if memcached was slightly faster, but 3X? I would be even more surprised if a put/insert was faster at all.
"This has been said many times. MySQL and memcached serve different purposes. Memcached is used to store processed data, while MySQL generally contains raw, normailized data, which needs lots of complex queries and other processing."
I actually mentioned this at the end of my post... So obviously I agree. But I have a feeling that people use memcached to cache a lot of data that is not very processed at all. Also, the last line is very misleading. You do not need to do much normalizing of your data. I can tell you that anybody doing federated database systems have to do a lot of de-normalizing of their data. And complex queries and other processing? That is just silly.
"Facebook needs memcache for the obvious reason that it's pages are highly complex and include many pictures."
Eh? Don't see how pictures would matter... But if Facebook is using memcache for HTML fragments, then I would agree that this is the right kind of cache. I don't know if this is the case or not. Other things like my list of friends or my contact info would be a poor choice for memached. Something like the Facebook feed... That is a lot tougher. There are limits to what you can cache, since the feed changes a lot and you might have a low tolerance for stale data. You might be able to create HTML fragments for the stories and cache those?
" Also, fewer of Facebooks pages are time-critical when compared to eBay. On eBay you basically can't cache a page rendering (memcache) if it has less than a minute
of auction time left"
Item listings are certainly time-critical, i.e you expect the price to be accurate when you are looking at a listing and considering bidding on it. This is true regardless of the time remaining, being less than a minute doesn't matter too much. However, that is just one page, many other pages are not so sensitive, but they are very dynamic.
When it comes to picking between MySQL and memcached, I would first say: are you using an ORM but need caching? If the data is being accessed through ORM, then your cache layer should be a database, not memcached. Again the only exception I could see to this would be a graph, i.e. data that is hard to describe relationally (requires self referential foreign keys, etc.)
Thursday, August 14, 2008
Cache Money
Scalability is a hard question, but a lot of people think that scalability is all about caching. In particular, memcached is the answer for caching. I think we can blame Facebook for this. Everybody knows that Facebook makes heavy use of memcached. Terry says that social graphs are a scalability problem for databases that is solved by memcached, so he is clearly drinking the Kool-Aid. The benefits of caching are obvious, but is memcached really the best/only way?
Earlier this year, eBay won an award from MySQL. This was for application we built that we originall Gem Cache. It is a caching tier that is built on top of MySQL. When the caching tier was designed, memcached was given a lot of consideration, but there were some very good advantages we got out of using MySQL instead.
First off, can MySQL be as fast as memcached? Absolutely. MySQL is aggressive about keeping things in memory, and if everything is in memory, it will be as fast as memcached. You can use MySQL's MEMORY engine, to accomplish this, or you can stick with MyISAM and let MySQL's caching put things in memory for you. Obviously you need to split your database, but we already knew how to do that efficiently. With that in mind, here are the advantages that MySQL offers.
1.) SQL Semantics. You are not limited to just simple "put" and "get." You can do selects and joins, aggregates, etc.
2.) Uniform Data Access. Do you use some kind of ORM? You can leverage this with a MySQL based cache.
3.) Write-through Caching. In a typical memcached setup, updates are still done to the database and this invalidates one or more objects in memcached. With a MySQL based cache, a row in the cache corresponds to a row in the "real" database. So we can write the cache and then asynchronously update the system of record.
4.) Read-through Cache. Similarly, you can always attempt to read from the cache database. If there is a cache miss, you can invisibly read from the real database and add to the cache at the same time.
5.) Replication. MySQL allows for replication of data, so it is easy to add redundancy and fail-over to your cache. Replication can also be useful when you have multiple data centers.
6.) Management. There are lots of great management tools for DBA, operations folks, etc. to use with MySQL.
7.) Cold starts. When your cache is a copy of database rows, it is easy to bootstrap it from your source, since the source and the cache are so similar.
8.) Eviction. Memcached gives you basic expiration, but otherwise you are handling eviction yourself. The caching in MySQL is a more useful LRU policy.
So there, just a few obvious advantages to using MySQL as a cache instead of memcached. Now I know that a lot of folks use MySQL as their "real" database, so it may seem weird to use it as a cache as well. But they are probably (hoepfully) using InnoDB for the "real" DB and that really is a different beast than MySQL with MyISAM or MEMORY tables. And it's not like you have to pay for extra licenses are anything... What are the advantages of memcached over MySQL? The only obvious one to me is if you want to cache things that don't fit in the database, like deep object graphs or HTML fragments, etc.
Earlier this year, eBay won an award from MySQL. This was for application we built that we originall Gem Cache. It is a caching tier that is built on top of MySQL. When the caching tier was designed, memcached was given a lot of consideration, but there were some very good advantages we got out of using MySQL instead.
First off, can MySQL be as fast as memcached? Absolutely. MySQL is aggressive about keeping things in memory, and if everything is in memory, it will be as fast as memcached. You can use MySQL's MEMORY engine, to accomplish this, or you can stick with MyISAM and let MySQL's caching put things in memory for you. Obviously you need to split your database, but we already knew how to do that efficiently. With that in mind, here are the advantages that MySQL offers.
1.) SQL Semantics. You are not limited to just simple "put" and "get." You can do selects and joins, aggregates, etc.
2.) Uniform Data Access. Do you use some kind of ORM? You can leverage this with a MySQL based cache.
3.) Write-through Caching. In a typical memcached setup, updates are still done to the database and this invalidates one or more objects in memcached. With a MySQL based cache, a row in the cache corresponds to a row in the "real" database. So we can write the cache and then asynchronously update the system of record.
4.) Read-through Cache. Similarly, you can always attempt to read from the cache database. If there is a cache miss, you can invisibly read from the real database and add to the cache at the same time.
5.) Replication. MySQL allows for replication of data, so it is easy to add redundancy and fail-over to your cache. Replication can also be useful when you have multiple data centers.
6.) Management. There are lots of great management tools for DBA, operations folks, etc. to use with MySQL.
7.) Cold starts. When your cache is a copy of database rows, it is easy to bootstrap it from your source, since the source and the cache are so similar.
8.) Eviction. Memcached gives you basic expiration, but otherwise you are handling eviction yourself. The caching in MySQL is a more useful LRU policy.
So there, just a few obvious advantages to using MySQL as a cache instead of memcached. Now I know that a lot of folks use MySQL as their "real" database, so it may seem weird to use it as a cache as well. But they are probably (hoepfully) using InnoDB for the "real" DB and that really is a different beast than MySQL with MyISAM or MEMORY tables. And it's not like you have to pay for extra licenses are anything... What are the advantages of memcached over MySQL? The only obvious one to me is if you want to cache things that don't fit in the database, like deep object graphs or HTML fragments, etc.
Tuesday, August 12, 2008
Netgear WNR2000
My trusty old D-Link DI624 started having problems recently. Actually it only started having problems immediately after a Comcast technician switched out our cable modem. Coincidence? Probably, but whatever...
I knew my Macbook was supported "Draft 2" of the 80211.n standard, so when I saw a reasonably priced 80211.n router, I went for it. "It" was a Netgear WNR2000. It installed very easily. I was able to re-use my old SSID and security settings, so that I did not to change any of my devices (two laptops and a Wii) or devices of friends and family who had previously used my network. Very nice. All of my devices accessed the new network with no problem. Happy happy joy joy! Not so fast.
Everything worked great except for my Macbook. It had no problems with the network, but its Internet connection was horrible. It was like being on dial-up, and it was only this way for my Macbook. My wife's laptop was blazing along as was our desktop computer (with a wired connection to the WNR2000.) It was only my Macbook that was badwidth impaired.
I started tweaking with the WNR2000's settings, well actually just one (wireless) setting: maximum network speed. This was set to 300 mpbs, or half the theoretical maximum for 80211.n and nearly six times as fast as my old DI-624's 80211.g network. I started tweaking it down, but to no effect. Until I set to 54 mpbs, i.e. the same speed as you get with 80211.g. Then my Internet connection on my Macbook was as fast as it was for every device on the network. Order had been restored, but it is not a satisfying solution.
My only guess is that I fell victim to some kind of "mixed" network issue, but that is mostly a guess. I thought the 80211.n would come in handy when copying files between my desktop computer and my Macbook. I do this a lot for music, photos, and videos. Now I basically have the same wireless network speed as before, but I could have gotten that with a cheaper router.
I knew my Macbook was supported "Draft 2" of the 80211.n standard, so when I saw a reasonably priced 80211.n router, I went for it. "It" was a Netgear WNR2000. It installed very easily. I was able to re-use my old SSID and security settings, so that I did not to change any of my devices (two laptops and a Wii) or devices of friends and family who had previously used my network. Very nice. All of my devices accessed the new network with no problem. Happy happy joy joy! Not so fast.
Everything worked great except for my Macbook. It had no problems with the network, but its Internet connection was horrible. It was like being on dial-up, and it was only this way for my Macbook. My wife's laptop was blazing along as was our desktop computer (with a wired connection to the WNR2000.) It was only my Macbook that was badwidth impaired.
I started tweaking with the WNR2000's settings, well actually just one (wireless) setting: maximum network speed. This was set to 300 mpbs, or half the theoretical maximum for 80211.n and nearly six times as fast as my old DI-624's 80211.g network. I started tweaking it down, but to no effect. Until I set to 54 mpbs, i.e. the same speed as you get with 80211.g. Then my Internet connection on my Macbook was as fast as it was for every device on the network. Order had been restored, but it is not a satisfying solution.
My only guess is that I fell victim to some kind of "mixed" network issue, but that is mostly a guess. I thought the 80211.n would come in handy when copying files between my desktop computer and my Macbook. I do this a lot for music, photos, and videos. Now I basically have the same wireless network speed as before, but I could have gotten that with a cheaper router.
Friday, August 08, 2008
Blogging Tools for Programmers
What kind of tools do you use for blogging? I am writing this, and most of my posts, in Blogger's web interface. I have tried a few other tools, but none of them are very good. There are some basic things that I want out of a blogging tool:
0.) Obviously it has to work with Blogger.
1.) Rich formatting. If nothing else I need to be able to easily create links. Full WYSIWYG editing would be great though. Don't make me do manual HTML formatting, but please don't prevent me either.
2.) Image hosting integration. I would like to be able to take either images on my local computer or off the web to include in the blog.
3.) Blogger tags/labels. I have a small blog, with about 100-150 unique viewers daily (as measure by MyBlogLog, which seems reliable.) There may be more folks who use blog reading tools, too, who knows. A decent number of the views come from people doing Google searches for "blah". These searches often lead to blog posts that I have tagged as "blah." No tagging means less visibility, so forget that.
4.) Offline mode would be nice. Really the first three thing are handled pretty well by Blogger's native web interface. But it would be nice to able to compose a post while offline.
5.) OSX. I blog on my MacBook almost exclusively and I do not want to boot Parallels just to blog. Integration with OSX spellchecker is pretty much implied too.
Does that seem like so much? I don't think so, but yet I have not found an acceptable solution for this. Seems like most desktop apps are designed for WordPress, TypePad, and Movable Type. I have tried things that are supposed to be great, like Mars Edit, and was underwhelmed. So even though nothing quite satisfies the above simple requirements, what I would really like is something that also supported:
6.) Code. I like to include code in my posts. It would be great to have something that made it easy for me to copy-n-paste code. It should escape special characters for me (like greater than and less than signs), provide code highlighting based on the language, and provide scrolling. Right now I use a PHP highlighter from Gilly. I had to hack in the CSS for this in one of my sidebar widgets. It works ok, but is a bit manual and the code often overflows.
Is there a tool like this out theere and I just don't know it? Is there a tool out there that does all of this but only with one of the other blogging platforms? If that were true, I would have to figure out how much pain would be involved with migrating... Maybe I should just build this using AIR?
0.) Obviously it has to work with Blogger.
1.) Rich formatting. If nothing else I need to be able to easily create links. Full WYSIWYG editing would be great though. Don't make me do manual HTML formatting, but please don't prevent me either.
2.) Image hosting integration. I would like to be able to take either images on my local computer or off the web to include in the blog.
3.) Blogger tags/labels. I have a small blog, with about 100-150 unique viewers daily (as measure by MyBlogLog, which seems reliable.) There may be more folks who use blog reading tools, too, who knows. A decent number of the views come from people doing Google searches for "blah". These searches often lead to blog posts that I have tagged as "blah." No tagging means less visibility, so forget that.
4.) Offline mode would be nice. Really the first three thing are handled pretty well by Blogger's native web interface. But it would be nice to able to compose a post while offline.
5.) OSX. I blog on my MacBook almost exclusively and I do not want to boot Parallels just to blog. Integration with OSX spellchecker is pretty much implied too.
Does that seem like so much? I don't think so, but yet I have not found an acceptable solution for this. Seems like most desktop apps are designed for WordPress, TypePad, and Movable Type. I have tried things that are supposed to be great, like Mars Edit, and was underwhelmed. So even though nothing quite satisfies the above simple requirements, what I would really like is something that also supported:
6.) Code. I like to include code in my posts. It would be great to have something that made it easy for me to copy-n-paste code. It should escape special characters for me (like greater than and less than signs), provide code highlighting based on the language, and provide scrolling. Right now I use a PHP highlighter from Gilly. I had to hack in the CSS for this in one of my sidebar widgets. It works ok, but is a bit manual and the code often overflows.
Is there a tool like this out theere and I just don't know it? Is there a tool out there that does all of this but only with one of the other blogging platforms? If that were true, I would have to figure out how much pain would be involved with migrating... Maybe I should just build this using AIR?
The Wrong Color of Green
 So apparently the folks in Green Bay didn't listen to me about the best way to resolve the Brett Favre situation. It's not like they are going to get a first or second round pick now, for the simple reason that Jets stink. Whatever. I'm glad we've still got Lilly. Anyways...
So apparently the folks in Green Bay didn't listen to me about the best way to resolve the Brett Favre situation. It's not like they are going to get a first or second round pick now, for the simple reason that Jets stink. Whatever. I'm glad we've still got Lilly. Anyways...I am not happy about Favre playing for the Jets. Of course, I think I know Green Bay's strategy here. They know that Favre will have to play against New England twice a year for as long as he stays unretired. They know that Belichick is an evil genius who likes nothing better than to cause his opponent's mind to implode.
Last year we learned about another little fetish of Belichick: football video. Think of all of the video of Favre that the Packers have accumulated. Think of all of the other goodies that might be laying around, like Rorscach test results, etc. Now imagine all of that in the hands of Belichick... Ted Thompson may just get the last laugh.
Update: Looks like trickle down economics works after all as Miami has signed Jets castoff Chad Pennington.
New developerWorks Articles: DWR and Google App Engine
This week, IBM developerWorks published two new articles that I wrote. The first article, is the third of the three part series I did on Ajax toolkits. This one is on Direct Web Remoting or DWR as it is commonly known. I had always been skeptical of DWR because of its RPC nature. However, after doing the article, I have to admit it is a pleasure to use. In the article I used the Java Persistence API (JPA) in combination with DWR. I was very pleased with being able to simply annotate some very simple, vanilla code and create an Ajax service that talked to a database. Ruby on Rails often seems magical to people in its ability to very easily work with databases and simplify Ajax development. DWR shows that you can do some pretty magical things in Java, too. DWR also makes Google Web Toolkit’s RPC code look ridiculous.
Speaking of Google (that is called a segue, if you are keeping score at home) the second article is the first of a three part series on the Google App Engine. I had mentioned some of the work on this here, and now you can read all about it on developerWorks. Of course you can also check out the application developed in the series, i.e. the aggroGator and you can get its source code here.
Speaking of Google (that is called a segue, if you are keeping score at home) the second article is the first of a three part series on the Google App Engine. I had mentioned some of the work on this here, and now you can read all about it on developerWorks. Of course you can also check out the application developed in the series, i.e. the aggroGator and you can get its source code here.