Thursday, March 29, 2007
Open Source Twitter
Monday, March 26, 2007
Happy to be Censored
 Now I'm sure they are probably just blocking all Blogger URLs, but I'm still flattered.
Now I'm sure they are probably just blocking all Blogger URLs, but I'm still flattered.
Sunday, March 25, 2007
Final Four
That being said, Florida was on a huge roll last year and UCLA folded mentally very early in the game. The Gators definitely aren't as hot as they were a year ago. The pressure to repeat has got to them. It won't be enough though, as they should beat UCLA pretty easily.
GWT, Eclipse, and JUnit -- Rants
The junitCreator seems even worse. It needs a GWT module name, but none of the artifacts created by the applicationCreator or projectCreator contain this. The .gwt.xml file has the module of course, but not it's name. It took me some trial and error to get this right. Even when I did, I could only launch my unit tests using the generated command line tools. I could launch these files directly from Eclipse, but I couldn't launch the unit tests using Eclipse. Thus I could not attach Eclipse's debugger.
I'm sure there's a way to do this. I'm sure that either I 1.)didn't use the right junitCreator command option, 2.) need to configure my project differently, or 3.) need to configure my run/debug profiles differently. Whatever this case, this is all very un-Ruby on Rails like.
Oh, one last complaint. The projectCreator has an option for generating an Ant file. That is borderline useless. The build file only builds a JAR and does not include the gwt compiler as part of the build. Guess what, if you're using gwt, you're building web applications. You don't need a JAR you need a WAR, and you need it to include all the web files, i.e. all that gwt-generated JavaScript. You need a web.xml file, which gwt knows how to generate (it creates one when you launch web mode.) WAR files have a very standardized structure, so this should not be very hard. Just package up what gets deployed to the bundled Tomcat in web mode.
Update: Strangely I don't have a lot of these same problems when I run everything on a Mac. No idea why, since even though the command line tools are platform specific and some of the runtime is platform specific, one would think that the underlying Java code that creates the projects, artifacts, etc. is pretty much the same.
Thursday, March 22, 2007
Adobe Apollo and Flex
So I downloaded a trial version of Adobe Flex Builder, plus the Apollo SDK and extensions for Flex Builder. It turns out that Flex Builder is built on Eclipse. That made me optimistic. Not only do I think Eclipse is a very smart platform to build on top of, but I know Eclipse really well. One would think that my familiarity with Eclipse would help me to be productive with Flex Builder.
A direct consequence of the Eclipse heritage is that there are two installations options for Flex Builder. You can install it "standalone" or as an Eclipse plugin. I have a lot of Eclipse plugins, but I've had some bad experiences with "bigger" plugins in the past. For example, when I was at Vitria, I was using Xml Spy for debugging complex XQuery expressions. I had the professional version of it, and it gave you the option of installing an Xml Spy-Eclipse plugin. I thought "cool, I can do my XQuery debugging inside Eclipse!" That may have been true, but I'll never know because it really hosed my Eclipse installation. I had to wipe it out and rebuild it. Rebuilding an Eclipse installation that involves lots of plugins is a real pain.
So needless to say that when confronted with a commercial application wanting to install itself inside Eclipse, I always decline. So I went with the standalone installation of Flex Builder. It was pretty quick and clean. One thing I noticed was that installed a JRE. Thankfully it only installed it inside its installation directory and it did not mess with any environment variables. I've been burned by Oracle installing its own JRE and then putting it on the path or even redefining $JAVA_HOME...
Still you would think that the Adobe installer would be a little smarter. It would be easy to detect if Java is present on the path. If it is, then don't bother installing a JRE and just use the system's JRE. Also, digging around I quickly found that the JRE they included was the HotSpot 1.4.2. Talk about old! Hopefully they'll skip 1.5 and move straight to 1.6. They may not get much advantage out of 1.5, but the speed improvement on 1.6 (particularly for a long-running process like an IDE) is definitely worth while.
Enough complaining about the installation... Here's what it looks like fresh out of the box on Windows.

Pretty similar to Eclipse. It seems like the big difference is the squarish windows. Of course the options in the menus are a lot different. They are very simplified with just options for creating Flex projects and objects. They did leave in the Software Updates, so you can easily install Eclipse plugins. That is very nice. All in all I am looking forward to building something Flashy.
Wednesday, March 21, 2007
Google Web Toolkit and Firebug
I like JavaScript, and I'm not worried that saying so will cause me to take a pay-cut. I have some tools I like to use to deal with it. One is a bookmarklet I found for viewing XMLHttpRequests and responses. It works really well in Internet Explorer 7.
I was playing with my little app on IE, and decided to open up my bookmarklet to see exactly what the GWT-generated JavaScript sent to the server. What did I see? Nothing at all...
Ok, time to get serious. I switched over to Firefox, where I have every web developer's best friend, Firebug, installed. I flipped the switch on Firebug and repeated the same process. What did I see here? Again nothing. Nada.
What the heck was going on? I see the request hitting the server and the response causing the data on the page to be changed. Yet somehow these common debugging tools were oblivious to what was going on. Was there an inviso-IFrame being used? That would be so Web 1.0-ish.
I probed around with Firebug, and indeed there was a massive hidden IFrame on my page. I opened it up and saw that there was a GWT-generated HTML page that was being dumped in here. That page contained tons of JavaScript. And not just any JavaScript, but amazingly obfuscated JavaScript. Here's a sample of it:
function gX(hX,iX){hX.aX = iX;}
function jX(kX){return kX.cX;}
function lX(mX,nX){mX.cX = nX;}
function oX(pX){return pX.bX;}
function qX(rX,sX){rX.bX = sX;}
function tX(uX,vX){uX.fo(eX(vX));uX.cq(jX(vX));uX.fo(oX(vX));}
function wX(xX,yX){gX(yX,xX.jo());lX(yX,xX.Ep());qX(yX,xX.jo());}
I don't know what to say about this stuff, but it's not the point. This wacky IFrame was where all the magic happened. It's the use of this IFrame and its Skynet-like JS that allows the GWT guys to claim:
Your GWT applications automatically support IE, Firefox, Mozilla, Safari, and Opera with no browser detection or special-casing within your code in most cases.
They're not using the sexiest flavor of AJAX, they're using the lowest-common-denominator version of it.
Tuesday, March 20, 2007
Monday, March 19, 2007
More Twittering
If you think about it though, you could probably consider Twitter to be a "high transaction" environment. A lot of people compare Twitter to IM clients, but it's really a lot different from a technical perspective. All the "tweets" are sent to the server and persisted (presumably in a database.) Hence the "transactions".
The other fun side must be sending out the updates to followers. There's two obvious ways to architect such a thing: pull or push. For pull, each user logged in would have some list of people they are following. A proxy for that user would have to constantly poll the server to see if there are any new updates. In push, you keep track of the people following each user. So if a user sends in an update, it needs to be pushed to the user's followers.
There are problems with either track, and typically an asynchronous pub-n-sub system would be used for something like this. Maybe Twitter does that. The trickiest part would be determining the subscribers. These would be people logged in on the website, obviously. But it would also be people with IM established and logged on to their IM (I guess they could try to send the IMs regardless if people are logged in or not.) Ditto for SMS. I guess if any of those criteria are met, then you could create a virtual subscriber for receiving updates and then relaying them appropriately. Of course you'll need a scheduler for creating these virtual clients, since one can turn off their SMS updates during certain hours of the day, etc.
Actually I think I would even turn the message persisting into a subscriber. That fits well with the AJAXy interface for it. You send a message and it goes into a queue. A subscriber representing your buddy picks it up and send it to your buddy's phone. Another subscriber representing a persistent store picks it up and saves it to tweet database. Seems pretty slick.
Yep, seems like it could be a fun system to put together. You've got to love a consumer site with lots of database transactions and asynchronous message queuing. Of course if I assume they did put the system together with lots of asynchronous parts, then it really better be bandwidth that's making them so unbearably slow. All the better reason to use IM or SMS for send/receive updates I suppose...
Sunday, March 18, 2007
March Madness
Saturday, March 17, 2007
Monday, March 12, 2007
Ecto-Mac
Update: The labels worked a little better. I got the little Technorati tags bit, just as Flock likes to put them. No Blogger labels, though, so this will probably not be a product I purchase.
Technorati Tags: ecto
Hiring at Startups
Let's take a break and enter the echo chamber for a moment... I was reading TSS and saw this blog on hiring at startups. It was somewhat interesting, though kind of "duh"-ish. Then I read a response from Don MacAskill, the CEO of SmugMug. There was one thing in here I had to completely disagreewith:
Hire for passion first, talent second.
Now I'm certainly no CEO, but I have been at my share of startups. I've also done a lot of interviewing and helped hire (and not hire) many people at said startups. There is no way I could agree with this statement. It reminds me of when sports broadcasters talk about "chemistry" people. It's a bunch of garbage.There is no substitute for talent.
I have worked with enthusiastic people who everybody loved. These were people willing to do whatever you asked them to do, work ridiculous hours, you name it. But they weren't good programmers. You know what happens? They struggle and it puts a drain on everybody else. Everybody else tries to help them out and cover for them, because they like the person and the person needs help.
I've also worked with very aloof, but brilliant people. These are the kind of people who you can go weeks without saying more than a few words to them. But they always deliver, and always deliver on-time. Often they over-deliver, i.e. they provide extra features that weren't asked for, but are immediately useful to everyone. But they keep to themselves, they don't run their mouths at company meetings, etc. Give me one of those people over two or three "passion first, talent second" sorts.
It's funny, just earlier I had been talking to a friend of mine about "geek syndrome" a.k.a. Asperger's Syndrome. This "syndrome" often suggests a correlation between highly logical intelligence and social "shortcomings." I would guess that such people would often fail the "passion" test.
Now I do have to give props to Mr. MacAskill for following up the bubbly-over-brains point with a much better one:
Passion for the job, not passion for the company.
He stole this from Google's Kathy Sierra, but at least he gives her credit. This is definitely true, and in some ways qualifies his previous false proposition. I'm still not sure if he would hire somebody who didn't care at all about SmugMug's business, but loved to code and was extremely good at it.
Ecto
I was reading this article on great Mac products and the very first one mentioned is a blog editor called Ecto. I was using my work laptop (Windows) when I read it, but noticed there was a Windows version. I decided to give it a try.
It uses the .NET framework, so there is a noticeable lag when it starts up. Maybe that will go away on Vista. Setting up my Blogger account required me to manually fetch the ID of blog and enter my credentials twice. The latter is just annoying, the former is something that I can't imagine most people doing.
The interface is pretty nice. It loaded all my old posts rapidly and allowed me to edit them easily. It also has nice support for Blogger's tagging system, err labels. It has nice integration with Flickr, allowing me to view my photostream from inside Ecto though I could only seem to insert a picture as a link, not an actual image.
All in all a promising product. I'll try it a few more times. I think the Mac is its "native" environment, so it might be better on there. Don't know if it's worth $$, but it's really pretty cheap ($18.)
Update: Turns out Ecto screws up Blogger's tagging/labels. That's something that Flock doesn't handle well either. That's too bad. Some MyBlogLog analysis shows that I get a lot of traffic via Google search for "foo" -> "foo" label on my blog. Definitely no $18 for the Windows version in that case. I'll try the Mac version tonight.
Saturday, March 10, 2007
Mode Problem
Given a list of N integers where more than half of the integers are the same, compute the mode (most common element) of the list.
When I came across the problem, the best I could immediately do was to compute the mode for any given set of numbers by putting the numbers into a heap using the frequency as the comparator. If you put the numbers in a heap like that then the mode is always at the root of the heap. It's equivalent to a heap sort, so it's a N*log(N) computation.
I knew this was not the best solution since it did not use the fact that the mode's frequency is greater than N/2. I mentioned the to my friend Chris and he figured out it was a classic Pigeonhole Principle problem.
His solution involved constructing dislike pairs of numbers. Basically you keep doing this until you can't. Eventually you won't be able to do it (because more than half of the numbers are the same) and the leftover will be the mode. Here's the code:
#include <iostream>
#include <vector>
using namespace std;
int mode(int*, int);
int main (int argc, char * const argv[]) {
vector<int> nums;
int n = 0;
while (n != -999){
cout << "Enter next number, -999 to quit" << endl;
scanf("%d",&n);
if (n != -999){
nums.push_back(n);
}
}
int sz = nums.size();
int* a = new int[sz];
for (int i=0;i<sz;i++){
a[i] = nums[i];
}
cout << "Mode: " << mode(a,sz);
return 0;
}
int mode(int* a, int n){
int* b = new int[n];
int j=0;
for (int i=0; i<n; i++){
if (i == j)
b[j] = a[i];
else if (a[i] == b[j])
b[2*i-j] = a[i];
else
b[(++j)++] = a[i];
}
return b[j];
}
Blogged with Flock
Wednesday, March 07, 2007
Google Desktop and Google Reader
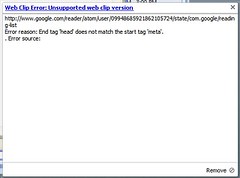 I guess Google Desktop is having problems with a feed from Google Reader. Notice it's an ATOM feed no less, ouch.
I guess Google Desktop is having problems with a feed from Google Reader. Notice it's an ATOM feed no less, ouch.Blogged with Flock
Album Artwork
I recently started using Last FM. I opened up Last FM on its "Now Playing" tab. It showed the artwork for "Back in Black". I clicked on it and it opened the Last FM in Firefox. I then right-clicked on "Hells Bells" in iTunes and selected "Get Info" and then the Artwork tab. I grabbed the artwork from Firefox and dragged it to the Artwork on iTunes, and somewhat surprisingly it just worked. Now I have artwork for any of my songs from "Back in Black." There could have been a few less clicks in the process, but it was still pretty intuitive and worked really well.
Blogged with Flock
Flocked Again
The RSS reader looks a lot nicer. There is integration with YouTube, which is very cool. It is running on the Firefox 2.0 code, so everything renders much quicker. Now if only there was a way to sync my RSS metadata between Flock on my work and home computers...
Blogged with Flock
Oracle XE
I wanted to install Oracle, something I often hate to do. I decided to install Oracle's slim personal database, Oracle XE. I only needed something for running a simple query (that required Oracle's SQL syntax, more on that later) and maybe a little development.
Oracle has a browser based client, which is actually pretty cool. Only problem is that it must install a web server for this and on my system it installed this on port 8080. I normally run Tomcat on port 8080. I tried to figure out how to change this inside Oracle. No luck. However, I found a great blog post that mentioned how to solve this.
Now on to what I wanted to do with Oracle. A co-worker had mentioned a SQL brain-teaser. Let's say you have a table, let's call it users, with exactly one column name. This column is not only not a primary key for the table, it is not unique. So you could have multiple instances of "John". Let's say there are three "John"s. You want to delete all of them but one, and you want to do this for any value of name that occurs more than once. The key is to do it with one SQL statement.
The obvious answer to me was to copy all the data into a temp table, but copy it uniquely. Then truncate the frist table, and copy the data back into it. That's three SQL statements though, and that's using an insert select statement as part of the create table statement.
Another way was to add a column to users and put in some sequence of numbers in that column. Then you can use that column as part of your where clause. I realized that Oracle does that auotmatically for you with its meta-column rowid. So that's why I wanted to install Oracle and try it out. Here's the SQL statement:
delete from users a where exists (select b.name from users b where a.name=b.name and b.rowid > a.rowid);
Monday, March 05, 2007
Mega Millions
In case you haven't heard... tomorrow night's Mega Millions jackpot is $340 million. My family is playing a bunch of tickets, so I wrote a little program designed to maximize the chance of our ticket being the only winning ticket. It's pretty crude, but it was fun to code it up in C++.
#include <string>
#include <cstdlib>
#include <list>
#include <vector>
#include <sstream>
#include <time.h>
using namespace std;
class Lotto{
private :
int length;
int maxNum;
int maxMegaNum;
int minNum;
int numTickets;
string ticketString(int *ticket){
ostringstream str;
for (int i=0; i<= this->length ; i++){
str << *ticket << " ";
ticket++;
}
return str.str();
}
/*
This is very crude. Multiply all the numbers in the first
ticket together. Go through the second ticket and make
sure that each of its numbers divides evenly into the product.
This wouldn't work if the maxNum was huge, but it is fast
and effective for small maxNum.
*/
int sameTickets(int *t1, int *t2){
int *runner = t1;
int prod = 1;
for (int i=0;i< this->length; i++){
prod *= *runner;
runner++;
}
runner = t2;
for (int i=0;i< this->length; i++){
if (prod % *runner != 0){
return 0;
}
runner++;
}
return 1;
}
int* generateTicket(){
const int delta = this->maxNum - this->minNum;
int *picked = new int[delta];
for (int j=0; j< delta; j++){
picked[j] = 0;
}
int i =0;
int *ticket = new int[this->length + 1];
while (i < this->length){
int num = rand() % delta;
int ticketNum= num + this->minNum;
if (picked[num] == 0){
ticket[i] = ticketNum;
i++;
picked[num] = 1;
}
}
// calc mega
ticket[this->length] = this->minNum + (rand() % (this->maxMegaNum - this->minNum));
free(picked);
return ticket;
}
public:
Lotto(int length, int maxNum, int maxMega, int minNum, int numTickets){
this->length = length;
this->maxNum = maxNum;
this->maxMegaNum = maxMega;
this->minNum = minNum;
this->numTickets = numTickets;
srand(time(NULL));
}
~Lotto(){
}
list<string> generateTickets(){
list<string> l;
vector<int*> v;
for (int i=0; i < this->numTickets ; i++){
int *ticket = this->generateTicket();
// check if same ticket already exists
int comparison = 0;
for (int j=0; j< v.size() ; j++){
comparison = this->sameTickets(ticket, v[j]);
if (comparison == 1){
break;
}
}
if (comparison == 0){
string str = this->ticketString(ticket);
l.push_front(str);
v.push_back(ticket);
} else {
// dupe tickets, decrement counter to generate new ticket
i--;
}
}
return l;
}
};
int main () {
cout << "How many (non-Mega) numbers on a ticket?" << endl;
int tixSize;
scanf("%d",&tixSize);
cout << "What's the largest number you can play?" << endl;
int tixMax;
scanf("%d",&tixMax);
cout << "What's the max Mega number you can play?" << endl;
int mega;
scanf("%d",&mega);
cout << "How many tickets do you want?" << endl;
int numTix;
scanf("%d",&numTix);
Lotto lotto = Lotto(tixSize, tixMax, mega, 32, numTix);
list<string> tickets = lotto.generateTickets();
int size = tickets.size();
for (int i=0; i < size ; i++){
string ticket = tickets.front();
tickets.pop_front();
cout << "Ticket: " << ticket << endl;
}
string text;
cout << "Press return to exit.." << endl;
getline(cin,text);
getline(cin,text);
return 0;
}
technorati tags:c++, lotto, mega millions
Safari Slowdown
Sunday, March 04, 2007
MacBook Pro Battery Life
I've been using a MacBook Pro (15", Core Duo 2GHz, Radeon X1600 about 6 months old) for the last week or so. I used to have an iBook that I bought in 2001. It had really great battery life, especially for a laptop of that era. I have a Dell that is very similar to the MacBook Pro (also 15", Core Duo 1.8 GHz, integrated graphics.) It gets excellent battery life. I'm almost always using it with the wireless card turned on and it gets around 3 hours of battery life. If I turn the wireless off, like I've done on an airplane for example, it will easily get 4+ hours of battery life. I expected something similar from the MacBook Pro. Maybe a little less battery life since it has a slightly faster processor and a better graphics card.
Nope. The battery life is awful. I get around an hour of battery life with the wireless card on. I manually turn the brightness way down on the display. I have the power setting for "Better Battery Life". I keep Bluetooth turned off at all times. Still maybe an hour of battery life. What's worse, is that it tells me I have more battery time left than I actually have. I don't get any kind of warning. I'll just be typing away at something and the thing goes to sleep unexpectedly. Really annoying.
I love the MacBook otherwise. It will be nice when Office is compiled as a universal binary so it will perform a little better, but everything else I use on here runs really fast. My only other complaing is that it gets extremely hot. I think that's a combination of it being so thin, having a metallic skin, and relying on passive cooling to keep it quiet. No big deal. Bad battery life and buggy management of it? Very big deal.
technorati tags:apple, mac, battery life, macbook pro
Saturday, March 03, 2007
Breaking 200
I've been working on losing weight since August 2004. I started by reducing how much I eat and then later started running and cycling. I started off at 343 lbs. A little less than a year ago I passed the 100 lbs lost mark. It was a nice feeling. Today, I dropped under 200 lbs for the first time since ... early teens? I'm not sure exactly, but it's been a long time.

Friday, March 02, 2007
Code Coverage Insanity
I saw this article on OnJava about so called Statement, Branch, and Path Coverage. The gist was that even if your code coverage was good, there could be different paths of execution that aren't being tested. This is obviously true, and I would think most programmers would roll their eyes and say "duh" to this.
The author offers up the Statement and Branch coverages as ways to analyze such a problem, but ultimately dismisses these methods as inadequate. He then offers up Path Coverage. In his section on Path Coverage he brings up two points:
Fortunately, you can use a metric called cyclomatic complexity to reduce the number of paths you need to test.
Ah, the magic phrase. It's the only thing that came to my mind when I read the title. The author then goes out on a limb and says:
Keep your code simple. The lower the cyclomatic complexity of your methods, the better.
He then describes how by determing the cyclomatic complexity, you can then enumerate the scenarios that need to be tested.
This guy's heart is in the right place, but massively enumerated test paths is the worst-case scenario. Just reduce the complexity. It's so much easier than writing thousands of test cases and the accompanying data. Not to mention that it actually improves your code. I'll go out on a limb and say that if you need to enumerate through many test cases because of high complexity, you're going to have bugs. It doesn't matter if you write all these test cases and all this test data. Unit testing can't always save poor design and/or bad code.
technorati tags:java, cyclomatic complexity, unit testing, metrics
Thursday, March 01, 2007
Subscribe to:
Posts (Atom)